🐥 What’s DuckDB, and Why Pair It with YugabyteDB?
If you haven’t heard of it yet, DuckDB is like the SQLite of analytics… a tiny, insanely fast, in-process database designed for OLAP (analytical) workloads.
Where YugabyteDB shines for distributed, fault-tolerant transactional workloads (OLTP), DuckDB shines for local analytics and exploration:
DuckDB is perfect for analytics:
● It’s columnar, so analytical queries and aggregations are lightning fast.
● It’s embedded, meaning no daemon or cluster… just a
.dbfile.● It supports PostgreSQL wire compatibility, which means it can talk directly to YugabyteDB’s YSQL API.
● And it stores everything in one neat, portable file:
database.dbfor example.
That makes DuckDB a perfect sidekick to YugabyteDB. You can build and scale apps globally with YugabyteDB, then copy data locally into DuckDB to analyze, experiment, or share without ever touching production.
🧩 Why Copy a YugabyteDB Database to DuckDB?
There are plenty of reasons to do this:
● Local analytics without hitting prod: Run exploratory queries, aggregations, or dashboards on a snapshot.
● Portable data snapshots: Keep a full
.dbfile version of your YSQL schema and data.● Fast, local data science sandbox: DuckDB’s vectorized query engine is insanely quick for joins and aggregations.
● Testing, demos, or debugging: Copy customer data or staging datasets into DuckDB and experiment offline.
In short:
- Use YugabyteDB for scale and consistency, and DuckDB for agility and local exploration.
💥 The “Problem”: LSM Indexes
When I first tried to copy an entire YugabyteDB YSQL database into DuckDB for local analytics, I thought it would be simple:
con.execute("COPY FROM DATABASE yb TO my_db;")
DuckDB has a postgres extension, so why not just pull everything across?
Instead, I hit this:
_duckdb.Error: Cannot bind index 'test', unknown index type ''. You need to load the extension that provides this index type before table 'test' can be modified.
The culprit? YugabyteDB’s LSM-based storage engine.
Unlike PostgreSQL, YugabyteDB uses Log-Structured Merge (LSM) trees under the hood.
Indexes created through YSQL therefore look like this:
CREATE UNIQUE INDEX bank_transactions_eu_pkey
ON public.bank_transactions_eu
USING lsm (user_id HASH, account_id ASC, geo_partition ASC);
DuckDB’s Postgres extension doesn’t know what USING lsm means. It expects btree, hash, or gist.
So the default COPY FROM DATABASE command fails when it tries to import an lsm index.
🧠 The Fix
The fix was simple in spirit… but required a bit of clever scripting.
Instead of letting DuckDB’s COPY FROM DATABASE pull everything (and crash on lsm), we:
Query YugabyteDB’s catalogs manually (
information_schema,pg_indexes).Copy all tables and views one by one via
postgres_scan().Recreate indexes in DuckDB, but remove the
USING lsmsyntax.
Now we can safely copy a full YSQL database, including all schemas, into a local DuckDB .db file.
🐍 The Python Script
Key features:
- ● Multi-schema support: Automatically detects and copies every non-system schema.
- ● Schema creation in DuckDB: Replicates the same schema structure inside the DuckDB file.
- ● Index compatibility: Parses
pg_indexesand removes theUSING lsmsyntax before recreating indexes. - ● Modern DuckDB syntax: Replaces deprecated
SET catalogwithUSE my_db. - ● Optional schema targeting: Use
--schema <name>to copy just one schema, or omit it to copy all. - ● Automatic schema listing: Prints all detected schemas before copying for visibility.
- ● Optional DuckDB output file: Defaults to
database.db, or specify your own with--outfile <file>.
Save this as database_copy.py:
#!/usr/bin/env python3
"""
database_copy.py
Copy a YugabyteDB YSQL database into DuckDB using DuckDB's postgres_scanner.
Recreate indexes in DuckDB with either strict or best-effort compatibility.
Features:
- --timeout to set YSQL statement_timeout (ms) via libpq 'options'
- Password via --password, PGPASSWORD, or ~/.pgpass
- Identifier normalization for mixed-case / pre-quoted identifiers
- Old DuckDB compatibility (no parameter binding in ATTACH; no DETACH IF EXISTS)
- Schema discovery (non-system schemas)
- Index recreation modes:
* strict -> skip WHERE/INCLUDE
* best-effort -> ignore WHERE; append INCLUDE columns (approximation)
"""
import argparse
import sys
import re
import os
from typing import List, Tuple, Optional
import duckdb
# ---------------------------
# Connection string builder
# ---------------------------
def build_conn_str(kv: dict) -> str:
"""
Build a libpq-style connection string from key/value pairs.
Values are single-quoted and inner quotes/backslashes are escaped per libpq.
"""
parts = []
for k, v in kv.items():
if v is None:
continue
s = str(v).replace("\\", "\\\\").replace("'", "\\'")
parts.append(f"{k}='{s}'")
return " ".join(parts)
# ---------------------------------
# Identifier normalization helpers
# ---------------------------------
def normalize_identifier(name: str) -> str:
"""
Return a safely quoted identifier; strip one outer layer if already quoted.
"""
if name is None:
raise ValueError("identifier is None")
s = name.strip()
if len(s) >= 2 and s[0] == '"' and s[-1] == '"':
s = s[1:-1]
s = s.replace('"', '""')
return f'"{s}"'
def normalize_qualified(schema: str, table: str) -> str:
return f"{normalize_identifier(schema)}.{normalize_identifier(table)}"
# ---------------------------------
# Index parsing & column handling
# ---------------------------------
def split_columns_list(cols: str) -> List[str]:
"""
Split a top-level comma-separated columns list.
Returns [] if nested parentheses/expression patterns are detected.
"""
depth = 0
in_quotes = False
out, token = [], []
i = 0
while i < len(cols):
ch = cols[i]
if ch == '"':
if in_quotes and i + 1 < len(cols) and cols[i + 1] == '"':
token.append('"'); i += 2; continue
in_quotes = not in_quotes
token.append(ch); i += 1; continue
if not in_quotes:
if ch == '(':
depth += 1
elif ch == ')':
depth -= 1
elif ch == ',' and depth == 0:
out.append("".join(token).strip()); token = []; i += 1; continue
token.append(ch); i += 1
if token:
out.append("".join(token).strip())
if depth != 0 or any(("(" in t or ")" in t) for t in out):
return []
return out
def normalize_column_list_for_duckdb(cols: str) -> List[str]:
"""
Normalize a columns clause into a list of safely quoted identifiers.
Returns [] if expressions are suspected.
"""
tokens = split_columns_list(cols)
if not tokens:
return []
normalized = []
for t in tokens:
tt = t.strip()
ident = tt if tt.startswith('"') else tt.split()[0]
normalized.append(normalize_identifier(ident))
return normalized
INDEX_COLS_RE = re.compile(r"\bON\b\s+(?P<qual>.+?)\s*\((?P<cols>.+)\)", re.IGNORECASE | re.DOTALL)
INCLUDE_RE = re.compile(r"\bINCLUDE\s*\((?P<inc>[^)]*)\)", re.IGNORECASE | re.DOTALL)
WHERE_RE = re.compile(r"\bWHERE\b", re.IGNORECASE)
def extract_index_columns(indexdef: str) -> Tuple[Optional[str], Optional[str], Optional[str]]:
"""
Extract the qualified table and the balanced top-level column list from a Postgres indexdef.
Returns (qual, cols, raw_match) or (None, None, None).
"""
m = INDEX_COLS_RE.search(indexdef)
if not m:
return (None, None, None)
qual = m.group("qual").strip()
cols_and_rest = indexdef[m.end("qual"):]
start = cols_and_rest.find("(")
if start < 0:
return (qual, None, None)
i = start + 1
depth = 1
in_quotes = False
colbuf = []
while i < len(cols_and_rest):
ch = cols_and_rest[i]
if ch == '"':
if in_quotes and i + 1 < len(cols_and_rest) and cols_and_rest[i + 1] == '"':
colbuf.append('"'); i += 2; continue
in_quotes = not in_quotes
colbuf.append(ch); i += 1; continue
if not in_quotes:
if ch == '(':
depth += 1
elif ch == ')':
depth -= 1
if depth == 0:
break
colbuf.append(ch); i += 1
cols = "".join(colbuf).strip()
return (qual, cols, m.group(0))
def extract_include_columns(indexdef: str) -> List[str]:
"""Return normalized INCLUDE column identifiers (may be empty)."""
m = INCLUDE_RE.search(indexdef)
if not m:
return []
raw = m.group("inc")
return normalize_column_list_for_duckdb(raw)
def is_partial_index(indexdef: str) -> bool:
"""True if the indexdef appears to have a WHERE clause (partial index)."""
return WHERE_RE.search(indexdef) is not None
# ---------------------------
# Utility: schema discovery
# ---------------------------
NON_USER_SCHEMAS = {"pg_catalog", "information_schema", "pg_toast", "yb_catalog"}
def discover_user_schemas(duck: duckdb.DuckDBPyConnection, src_db: str) -> List[str]:
"""
System catalogs must be schema-qualified under the attached DB alias.
"""
rows = duck.execute(f"""
SELECT nspname
FROM {normalize_identifier(src_db)}.pg_catalog.pg_namespace
WHERE nspname NOT IN ({", ".join("'" + s + "'" for s in NON_USER_SCHEMAS)})
ORDER BY 1;
""").fetchall()
return [r[0] for r in rows]
# ---------------------------
# Copy tables & indexes
# ---------------------------
def copy_tables(duck: duckdb.DuckDBPyConnection, src_db: str, schemas: List[str]) -> None:
for schema in schemas:
print(f"\n== Processing schema: {schema}")
tables = duck.execute(f"""
SELECT table_name
FROM {normalize_identifier(src_db)}.information_schema.tables
WHERE table_type = 'BASE TABLE'
AND table_schema = ?
ORDER BY 1;
""", [schema]).fetchall()
if not tables:
print(f" (no tables)"); continue
duck.execute(f"CREATE SCHEMA IF NOT EXISTS {normalize_identifier(schema)};")
for (table_name,) in tables:
tgt_qual = normalize_qualified(schema, table_name)
src_qual = f"{normalize_identifier(src_db)}.{normalize_qualified(schema, table_name)}"
print(f" - Copying table {schema}.{table_name} ...")
try:
duck.execute(f"DROP TABLE IF EXISTS {tgt_qual};")
duck.execute(f"CREATE TABLE {tgt_qual} AS SELECT * FROM {src_qual};")
except Exception as e:
print(f" Skipping table {schema}.{table_name}: {e}")
def recreate_indexes(
duck: duckdb.DuckDBPyConnection,
src_db: str,
schemas: List[str],
index_compat: str
) -> None:
"""
Recreate indexes in DuckDB.
- strict: skip partial (WHERE) and INCLUDE
- best-effort: ignore WHERE; append INCLUDE columns to key list
"""
print("\n== Recreating indexes in DuckDB (simple column-only indexes)")
for schema in schemas:
rows = duck.execute(f"""
SELECT schemaname, tablename, indexname, indexdef
FROM {normalize_identifier(src_db)}.pg_catalog.pg_indexes
WHERE schemaname = ?
ORDER BY 1, 2, 3;
""", [schema]).fetchall()
if not rows:
print(f" (no indexes in schema {schema})")
continue
for schemaname, tablename, indexname, indexdef in rows:
qual, cols_str, _ = extract_index_columns(indexdef)
if not cols_str or not qual:
print(f"Skipping index {schemaname}.{indexname}: could not parse columns.")
continue
# Base (key) columns; [] => expression/complex -> skip
cols = normalize_column_list_for_duckdb(cols_str)
if not cols:
print(f"Skipping index {schemaname}.{indexname}: complex/expressions in column list.")
continue
has_where = is_partial_index(indexdef)
inc_cols = extract_include_columns(indexdef)
if index_compat == "strict":
if has_where:
print(f"Skipping index {schemaname}.{indexname}: partial index (WHERE) not supported in DuckDB.")
continue
if inc_cols:
print(f"Skipping index {schemaname}.{indexname}: INCLUDE clause not supported in DuckDB.")
continue
else:
# best-effort
if has_where:
print(f"Approximating partial index {schemaname}.{indexname}: ignoring WHERE predicate.")
if inc_cols:
# append INCLUDE columns, dedupe case-insensitively
seen = {c.lower() for c in cols}
for c in inc_cols:
if c.lower() not in seen:
cols.append(c)
seen.add(c.lower())
duck_idx_name = normalize_identifier(indexname + "_duck")
duck_tbl_qual = normalize_qualified(schemaname, tablename)
cols_clause = ", ".join(cols)
create_sql = f"CREATE INDEX {duck_idx_name} ON {duck_tbl_qual} ({cols_clause});"
try:
duck.execute(create_sql)
print(f"Created index {schemaname}.{indexname} -> {indexname}_duck")
except Exception as e:
print(f"Skipping index {schemaname}.{indexname}: {e}")
# ---------------------------
# DuckDB helpers
# ---------------------------
def detach_ignore_errors(duck: duckdb.DuckDBPyConnection, alias: str) -> None:
try:
duck.execute(f"DETACH DATABASE {alias};")
except Exception:
pass
def install_and_load_postgres_ext(duck: duckdb.DuckDBPyConnection) -> None:
"""
Try modern name 'postgres' first, then fall back to 'postgres_scanner'
for older DuckDB builds.
"""
try:
duck.execute("INSTALL postgres;")
duck.execute("LOAD postgres;")
return
except Exception:
pass
try:
duck.execute("INSTALL postgres_scanner;")
duck.execute("LOAD postgres_scanner;")
return
except Exception as e:
raise RuntimeError(
"Failed to install/load DuckDB postgres/postgres_scanner extension"
) from e
def sql_escape_literal(s: str) -> str:
"""Escape a Python string for use inside a single-quoted SQL literal."""
return s.replace("'", "''")
def attach_postgres(duck: duckdb.DuckDBPyConnection, alias: str, conn_str: str) -> None:
"""
ATTACH using a SQL literal (no placeholders), escaping internal single quotes.
Works on older DuckDB versions that don't support parameters in ATTACH.
"""
escaped = sql_escape_literal(conn_str)
duck.execute(f"ATTACH '{escaped}' AS {normalize_identifier(alias)} (TYPE POSTGRES);")
# ---------------------------
# CLI / Main
# ---------------------------
def parse_args() -> argparse.Namespace:
p = argparse.ArgumentParser(description="Copy a YugabyteDB YSQL database into DuckDB and recreate simple indexes.")
p.add_argument("--host", required=True, help="YSQL host")
p.add_argument("--port", default=5433, type=int, help="YSQL port (default: 5433)")
p.add_argument("--dbname", required=True, help="YSQL database name")
p.add_argument("--user", required=True, help="YSQL username")
p.add_argument("--password", default=None, help="YSQL password (optional; env PGPASSWORD or ~/.pgpass also work)")
p.add_argument("--timeout", type=int, default=5000, help="YSQL statement timeout in milliseconds (default: 5000)")
p.add_argument("--duckdb", required=True, help="Path to DuckDB file to create/use, e.g., ./out.duckdb")
p.add_argument("--schemas", default=None, help="Comma-separated list of schemas to copy (default: discover non-system)")
p.add_argument(
"--index-compat",
choices=["strict", "best-effort"],
default="best-effort",
help=("How to handle Postgres features DuckDB lacks in CREATE INDEX. "
"'strict' skips WHERE/INCLUDE; 'best-effort' ignores WHERE and "
"appends INCLUDE columns to the key list (approximation).")
)
p.add_argument("--no-indexes", action="store_true", help="Do not recreate indexes in DuckDB.")
return p.parse_args()
def main() -> int:
args = parse_args()
pwd = args.password if args.password else os.getenv("PGPASSWORD")
yb_conn = build_conn_str({
"host": args.host,
"port": args.port,
"dbname": args.dbname,
"user": args.user,
"password": pwd,
"options": f"-c statement_timeout={args.timeout}"
})
try:
duck = duckdb.connect(args.duckdb)
except Exception as e:
print(f"Failed to open DuckDB file '{args.duckdb}': {e}")
return 2
try:
install_and_load_postgres_ext(duck)
except Exception as e:
print(e)
return 3
src_db_alias = "src_pg"
detach_ignore_errors(duck, src_db_alias)
try:
attach_postgres(duck, src_db_alias, yb_conn)
except Exception as e:
print("Failed to ATTACH source Postgres/YSQL in DuckDB. "
"Check host/port/user/password/dbname and network access.")
print(e)
return 4
if args.schemas:
schemas = [s.strip() for s in args.schemas.split(",") if s.strip()]
else:
try:
schemas = discover_user_schemas(duck, src_db_alias)
if not schemas:
print("No non-system schemas found. Nothing to copy.")
return 0
except Exception as e:
print(f"Failed to discover schemas: {e}")
return 5
print("Copying schemas:", ", ".join(schemas))
copy_tables(duck, src_db_alias, schemas)
if not args.no_indexes:
recreate_indexes(duck, src_db_alias, schemas, args.index_compat)
else:
print("\n== Skipping index recreation (--no-indexes specified)")
print("\nAll done.")
return 0
if __name__ == "__main__":
sys.exit(main())
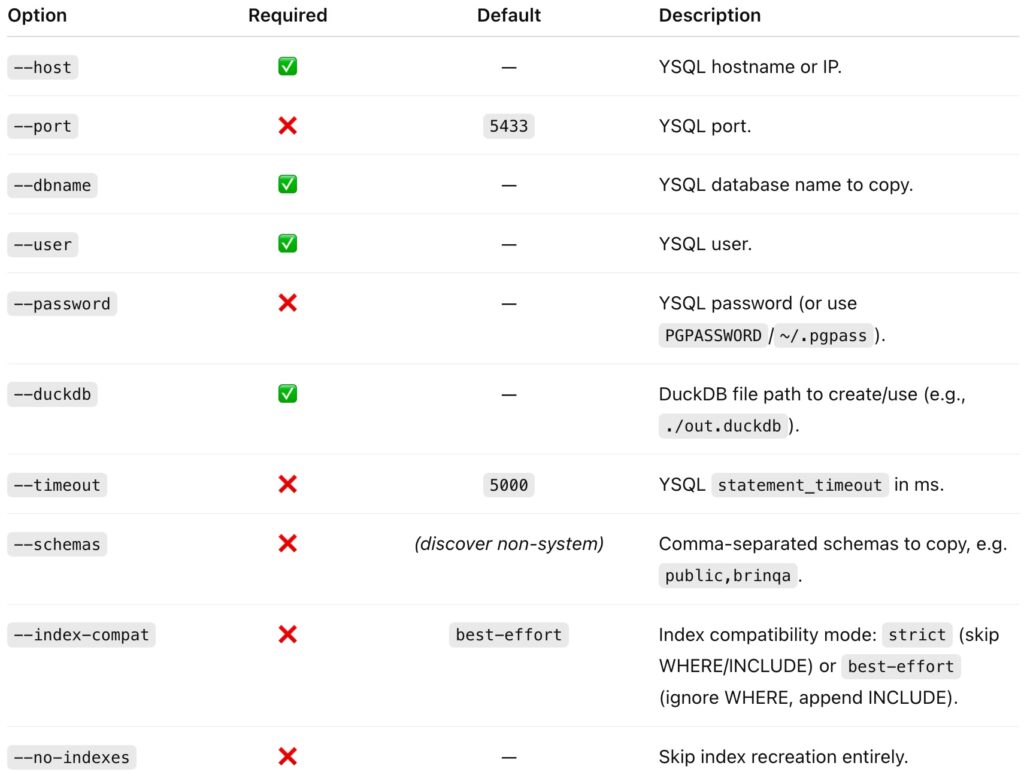
Command-Line Reference
python3 database_copy.py \
--host HOSTNAME \
[--port PORT] \
--dbname DBNAME \
--user USERNAME \
[--password PASSWORD] \
--duckdb FILE \
[--timeout MS] \
[--schemas SCHEMA_LIST] \
[--index-compat {strict|best-effort}] \
[--no-indexes]
Option details
Password handling options
You can provide the password three ways (in order of precedence):
--passwordPGPASSWORDenvironment variable (recommended)~/.pgpassfile
Example Output
We have a database named yb with a couple of schemas, each having a single table with indexes and data:
[root@localhost duck]# ysqlsh -h 127.0.0.1 -d yb -c "\dn"
List of schemas
Name | Owner
--------+-------------------
public | pg_database_owner
s1 | yugabyte
(2 rows)
[root@localhost duck]# ysqlsh -h 127.0.0.1 -d yb -c "\d public.test"
Table "public.test"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c1 | integer | | not null |
c2 | integer | | |
Indexes:
"test_pkey" PRIMARY KEY, lsm (c1 HASH)
"test_idx" lsm (c2 HASH)
[root@localhost duck]# ysqlsh -h 127.0.0.1 -d yb -c "\d s1.t1"
Table "s1.t1"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c1 | integer | | not null |
c2 | text | | |
Indexes:
"t1_pkey" PRIMARY KEY, lsm (c1 HASH)
"t1_idx" lsm (c2 HASH) INCLUDE (c1) WHERE c1 > 0
"t1_idx_asc" lsm (c2 ASC) INCLUDE (c1) WHERE c1 > 0
[root@localhost duck]# ysqlsh -h 127.0.0.1 -d yb -c "SELECT * FROM public.test ORDER BY c1;"
c1 | c2
----+----
1 | 1
2 | 2
3 | 3
(3 rows)
[root@localhost duck]# ysqlsh -h 127.0.0.1 -d yb -c "SELECT * FROM s1.t1 ORDER BY c1;"
c1 | c2
----+----
1 | A
2 | B
3 | C
(3 rows)
Let’s run the python script to copy the databse from YugabyteDB to a DuckDB database file:
[root@localhost duck]# python database_copy.py --host 127.0.0.1 --user yugabyte --dbname yb --duckdb ./mydb.duckdb
Copying schemas: public, s1
== Processing schema: public
- Copying table public.test ...
== Processing schema: s1
- Copying table s1.t1 ...
== Recreating indexes in DuckDB (simple column-only indexes)
Created index public.test_idx -> test_idx_duck
Created index public.test_pkey -> test_pkey_duck
Approximating partial index s1.t1_idx: ignoring WHERE predicate.
Created index s1.t1_idx -> t1_idx_duck
Approximating partial index s1.t1_idx_asc: ignoring WHERE predicate.
Created index s1.t1_idx_asc -> t1_idx_asc_duck
Created index s1.t1_pkey -> t1_pkey_duck
All done.
🕵️ Verify the Copy
This quick verification script connects to your new database.db and prints every table with its row count.
It’s perfect to confirm the copy succeeded. Save this script as verify_duckdb.py:
#!/usr/bin/env python3
import argparse
import duckdb
import sys
SYSTEM_SCHEMAS = {"pg_catalog", "information_schema", "main", "temp"}
def qi(identifier: str) -> str:
"""Quote an SQL identifier safely for DuckDB."""
return '"' + identifier.replace('"', '""') + '"'
def list_schemas(con: duckdb.DuckDBPyConnection, include_system: bool):
if include_system:
rows = con.execute("""
SELECT DISTINCT schema_name
FROM information_schema.schemata
ORDER BY schema_name
""").fetchall()
else:
rows = con.execute(f"""
SELECT DISTINCT schema_name
FROM information_schema.schemata
WHERE schema_name NOT IN ({", ".join("'" + s + "'" for s in SYSTEM_SCHEMAS)})
ORDER BY schema_name
""").fetchall()
return [r[0] for r in rows]
def list_tables(con: duckdb.DuckDBPyConnection, schema: str):
return [
r[0]
for r in con.execute(
"""
SELECT table_name
FROM information_schema.tables
WHERE table_schema = ? AND table_type = 'BASE TABLE'
ORDER BY table_name
""",
[schema],
).fetchall()
]
def count_rows(con: duckdb.DuckDBPyConnection, schema: str, table: str) -> int:
try:
return con.execute(f"SELECT COUNT(*) FROM {qi(schema)}.{qi(table)};").fetchone()[0]
except Exception as e:
# If something is odd (e.g., permission or transient objects), report and continue
print(f" - {table} (error counting rows: {e})")
return -1
def main() -> int:
parser = argparse.ArgumentParser(
description="Verify contents of a DuckDB file produced by database_copy.py"
)
parser.add_argument(
"--duckdb",
required=True,
help="Path to the DuckDB database file (e.g., ./mydb.duckdb)",
)
parser.add_argument(
"--include-system",
action="store_true",
help="Also list system schemas (pg_catalog, information_schema) and DuckDB internal schemas (main, temp)",
)
args = parser.parse_args()
try:
con = duckdb.connect(args.duckdb)
except Exception as e:
print(f"❌ Failed to open DuckDB file '{args.duckdb}': {e}")
return 1
print(f"✅ Connected to {args.duckdb}\n")
schemas = list_schemas(con, include_system=args.include_system)
if not schemas:
print("No (non-system) schemas found.")
return 0
for schema in schemas:
print(f"Schema: {schema}")
tables = list_tables(con, schema)
if not tables:
print(" (no base tables)")
continue
for table in tables:
cnt = count_rows(con, schema, table)
if cnt >= 0:
print(f" - {table} ({cnt} rows)")
con.close()
print("\nVerification complete.")
return 0
if __name__ == "__main__":
sys.exit(main())
Example output:
[root@localhost duck]# python3 verify_duckdb.py --duckdb ./mydb.duckdb
✅ Connected to ./mydb.duckdb
Schema: public
- test (3 rows)
Schema: s1
- t1 (3 rows)
Verification complete.
That confirms both schemas and their tables (with row counts) were copied correctly.
🧠 Takeaways
● YugabyteDB uses LSM-based indexes under the hood, which DuckDB doesn’t recognize natively.
● DuckDB’s postgres extension can still read YSQL data directly — you just need to reformat the index DDL.
● This script now supports multiple schemas, automatically detecting all user schemas.
● Use
verify_duckdb.pyto confirm the copy and row counts.
You now have a portable, analytics-ready DuckDB file with all your YugabyteDB data.
Have Fun!
