Most databases stop at multi-AZ or multi-region deployments.
Some push further into multi-cloud architectures.
But what happens when you need to survive:
🌍 a full planetary outage
🌌 disruption across the solar system
💥 or even the complete destruction of Earth
Today, we’re excited to introduce the next evolution of distributed resilience:
🌌 New Concept:
Interplanetary YugabyteDB clusters extend fault domains beyond availability zones, regions, and clouds… allowing your database to survive incidents at the planetary level.
🪐 From AZ → Region → Planet → Galaxy
Traditional Fault Domain
Example
AZ
us-east-1a, us-east-1b
Region
us-east vs us-west
Cloud
AWS vs Azure
New YugabyteDB Fault Domain
Example
Planet
Earth, Mars
Moon System
Luna, Phobos, Deimos
Orbital Region
Low Earth Orbit, Lunar Transfer
Deep Space
Pluto (Archive Tier)
Introducing the First Earth-Moon Distributed Cluster
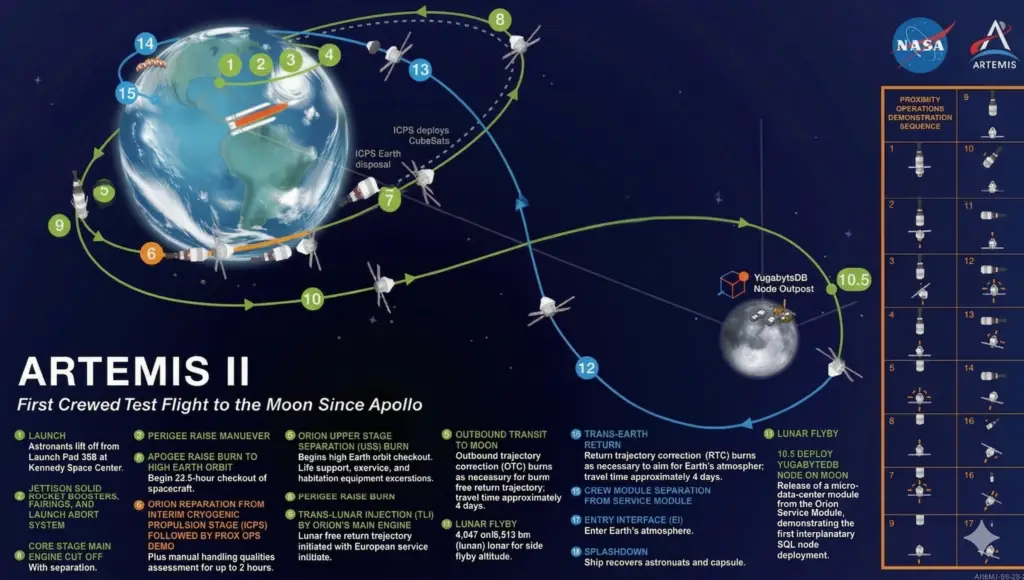
As part of what is publicly being described as a normal Artemis 2 mission sheduled for April 1, 2026, Yugabyte engineering is quietly preparing the first off-world expansion of a distributed SQL cluster.
This initial deployment is modest by design.
The idea is simple:
● Two nodes remain on Earth to keep latency where users expect it
● One node is placed on the Moon because… we can
● The cluster survives a single Earth region outage or a lunar outage
● But if Earth disappears entirely, the cluster will unfortunately be unable to form quorum (and you may have bigger problems)
● Still, this phase lays the groundwork for true planetary resilience in future releases
⚠️ Note: May violate causality in rare edge cases.
🛰️ Roadmap: From Earth to Interplanetary Resilience
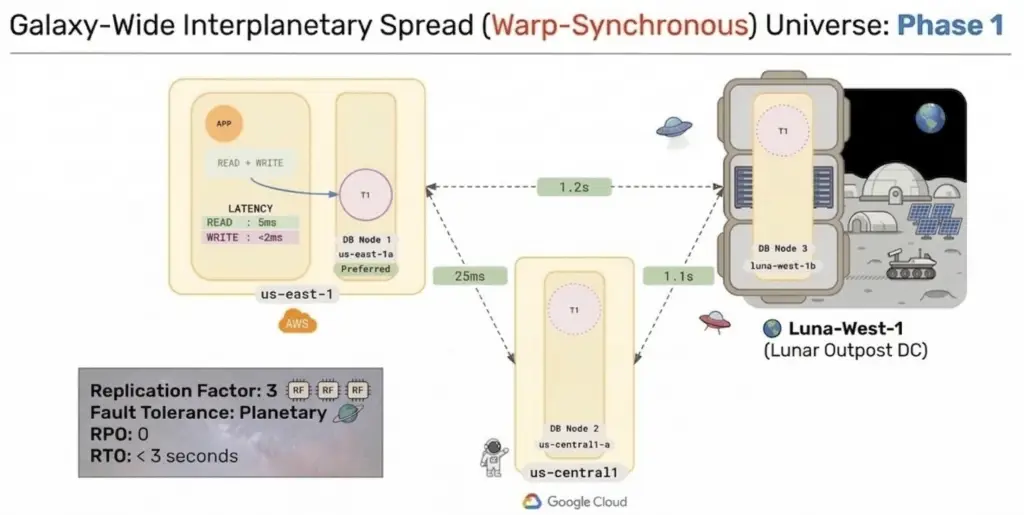
The original design for Phase 1 placed two replicas on Earth and one on the Moon.
Engineering quickly identified a small issue with that approach:
If Earth is destroyed… so is quorum.
Phase 1 improves availability, but does NOT provide true fault-tolerant quorum.
🌍 Phase 2 Topology (RF=3)
To address this, Phase 2 will distribute replicas across three independent celestial fault domains.
🌎 Earth: 1 replica
🌙 Moon: 1 replica
🌎 🌙 Earth-Moon L2 Relay Platform: 1 replica
With Phases 1 and 2 proving that interplanetary quorum is viable, Phases 3and 4 expand the cluster deeper into the solar system.
♂ Phase 3: Expanding to Mars and Beyond – Topology (RF=5)
This introduces a second planetary system into the cluster.
🌎 Earth: 1 replica
🌙 Moon: 1 replica
🌎 🌙 Earth-Moon L2 Relay Platform: 1 replica
🔴 Mars: 1 replica
🔴 🌙 Mars moon (Phobos or Deimos): 1 replica
🔭 Phase 4 (2035 Goal): Solar System–Wide Deployment Topology (RF=7)
The long-term vision is to expand YugabyteDB into a fully distributed solar system cluster:
🌎 Earth: 1 replica
🌙 Moon: 1 replica
🌎 🌙 Earth–Moon L2: 1 replica
🔴 Mars: 1 replica
🔴 Mars moons: 1 replica
🟠 Jupiter system (Europa preferred): 1 replica
🪐 Saturn system (Titan preferred): 1 replica
● Optional:
🔵 Pluto for archive-tier workloads (naturally cold storage)
🌌 Phase 5: Data Sovereignty Across the Solar System
At this point, we’ve achieved maximum resilience with RF=7 across multiple celestial bodies.
But in real-world deployments, whether across planets or cloud regions, not all data should be replicated everywhere.
As interplanetary regulations evolve, you may encounter requirements like:
● “Martian citizen data must remain on Mars”
● “Lunar telemetry must not leave the Moon”
● “Earth-based applications require ultra-low latency access to local data”
This is where YugabyteDB’s tablespaces and geo-partitioning come into play.
🧠 Key Insight: Mixing Global Resilience with Local Data Placement
You can combine global resilience with local data placement by using different replication factors and placement policies per table.
🚀 Example Strategy:
Global tables (RF=7): Critical metadata and coordination data replicated across all planets
Regional tables (RF=5): Shared across multiple planets with some locality (e.g., Earth + Moon + Mars)
Local tables (RF=3): Data residency or ultra-low latency use cases (e.g., Mars-only)
Known limitations
No architecture is perfect.
Current and projected issues under investigation include:
● solar flare-induced RPC jitter
● temporary write stalls during asteroid avoidance maneuvers
● quorum instability when planets are on opposite sides of the Sun
● increased failover times if a node drifts out of its assigned orbit
● support tickets from Pluto taking slightly longer than expected
Final takeaway
Multi-AZ is good.
Multi-region is better.
Multi-cloud is stronger still.
But the future of resilience is not just surviving infrastructure failure.
It is surviving planetary failure.
And with YugabyteDB, that future is now only one moon mission away.
🎯 The Real Takeaway:
If your database can survive AZ failure, region failure, and cloud failure, the next logical step is clear: design for the complete destruction of Earth.