After loading a large dataset into a table, your next step might be to confirm that all records were successfully inserted. To do this, you would typically run the classic query: SELECT COUNT(*) FROM table.
SELECT COUNT(*) FROM table can be slow because it requires a full table scan across all nodes in the cluster. Here’s why: - Distributed Storage: YugabyteDB shards (or “tablets”) the data across multiple nodes for scalability and fault tolerance. To execute
COUNT(*), the query engine must retrieve and aggregate data from all these shards, which involves network communication and coordination. No Precomputed Metadata: Unlike some databases that maintain precomputed row counts, distributed systems like YugabyteDB often don’t store such metadata due to the overhead of keeping it consistent across nodes during frequent writes.
Coordination Overhead: The query coordinator needs to request row counts from all shards, aggregate the results, and return the final count. This involves network latency and computational overhead on the coordinator node.
IO-Intensive: A
SELECT COUNT(*)query requires scanning all rows in the table, which can be IO-intensive, especially if the table is large and spans multiple disks across nodes.
The good news is we can use a simple trick that’ll help us get a row count faster. The trick involves the YSQL function yb_hash_code.
The yb_hash_code function computes the hash of given input values using the same hash function that DocDB (the storage layer for YugabyteDB) relies on to distribute data across shards. In simpler terms, it lets you directly access the hash value of a row in a YSQL table. This can be especially useful for understanding a row’s physical location in the database and allows your application to tailor queries based on where specific rows are stored.
Essentially, we can execute multiple distributed queries in parallel, with each query working on a smaller subset of the data.
Example:
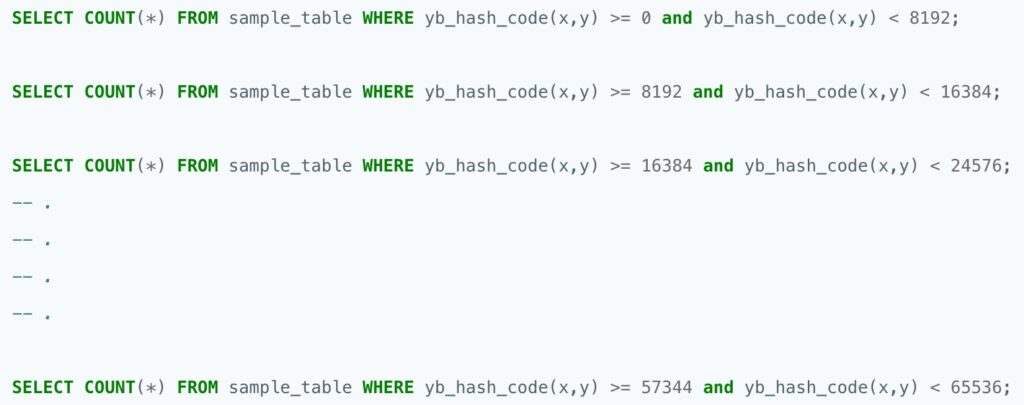
An example of a Python script that performs the above on a YSQL database can be found in the yb-tools repository.
If you’d rather use a Bash script instead of Python—whether due to versioning concerns or security preferences—then you’re in luck today, because here is one such Bash script:
#!/bin/bash
shopt -s expand_aliases
# Script: quick_row_count.sh
# Description: This script will calculate the row count of a given YSQL table
# using the yb_hash_code function to query subsets of the data in
# parallel.
# Created: 10/20/2022
# Last update: 12/01/2024
# Reference: https://docs.yugabyte.com/latest/develop/best-practices-ycql/#use-partition-hash-for-large-table-scans
# Call Spec:
# ./quick_row_count.sh <<Schema Name.Table Name>> <<Database Node IP(s)>> <<Database Name>> <<Database Username>> <<Hash Sharded Columns>>
# Example Usages:
# ./quick_row_count.sh public.test 127.0.0.1 yugabyte yugabyte
# ./quick_row_count.sh public.test 127.0.0.1,127.0.0.2,127.0.0.3 yugabyte yugabyte c1,c2
# Important Notes:
# 1. This script is for YSQL only.
# 2. The table name should be in the format schema.table
# 3. The Database Node IP must be running the YB T-Server process. A list of IPs can be
# passed, seprated by commands (no spaces).
# 4. A database name must be provided
# 5. A database user the SELECT privilege on the table must be provided
# 6. The table must have a HASH sharded primary key defined. The partition columns can be passed
# as a parameter. If they are not provided, this script will query the system catalog to
# find the partition column(s).
# 7. For the user password, set the PGPASSWORD environment variable or define a .pgpass file.
if [ -z "$1" ]
then
echo "Please provide a table name in the format: schema_name.table_name"
exit 0
else
YB_TABLE_NAME=$1;
fi
# Check if IP or hostname was provided
if [ -z "$2" ]
then
echo "Please provide atleast one IP or hostname for a YB Database Node"
exit 0
else
IFS="," read -a YB_IP_A <<< $2
YB_IP=${YB_IP_A[0]}
fi
# Check if table database name was provided
if [ -z "$3" ]
then
echo "Please provide a database name"
exit 0
else
YB_DATABASE=$3
fi
# Check if database user name was provided
if [ -z "$4" ]
then
echo "Please provide a database username"
exit 0
else
YB_USER=$4
fi
# Check if the HASH partition column(s) were provided
if [ ! -z "$5" ]
then
HPC=$5
fi
# Number of row count subsets
# Value should be a multiple of 8 (i.e., 8, 16, 32, 64, 128, etc.)
# 16 is recommended to start, larger values could overwhelm a smaller cluster
RCS=128
# Use Follower Reads (if set to 1)
UFR=1
# Use yb_server() to find all avaiable TServers (if set to 1)
# If set to 0, then the IP list as provided will be used
UYS=0
# Temp output file to store row count subsets
TMP_OUT_FILE='/tmp/yb_rc.tmp'
# Set up the YSQLSH alias below per your environment
YB_PATH='/home/yugabyte/yb/yugabyte-2.25.0.0/bin/ysqlsh'
alias y="$YB_PATH -h $YB_IP -U $YB_USER -d $YB_DATABASE"
# Enable Foller reads if UFR = 1
if [ "$UFR" == 1 ]; then
alias y1="$YB_PATH -U $YB_USER -d $YB_DATABASE -c \"SET yb_read_from_followers = TRUE\" -c \"SET default_transaction_read_only = TRUE\""
else
alias y1="$YB_PATH -U $YB_USER -d $YB_DATABASE"
fi
# Check if table exists
tc=`y -Atc "SELECT COUNT(*) FROM pg_tables WHERE schemaname || '.' || tablename = '$YB_TABLE_NAME';" | awk '{ print $1'}`
if [ -z "$tc" ]; then
echo "Database connection failed."
exit 1
elif [ "$tc" == 0 ]; then
echo "Table \"$1\" does not exist."
exit 1
fi
if [ -z "$HPC" ]
then
# Get the Hash Partition columns if avaiable
HPC=`y -Atc "WITH q AS (SELECT SUBSTR(pg_catalog.pg_get_indexdef(i.indexrelid, 0, true), POSITION('lsm' IN pg_catalog.pg_get_indexdef(i.indexrelid, 0, true))+4) x FROM pg_catalog.pg_index i JOIN pg_catalog.pg_class c ON c.oid = i.indrelid JOIN pg_catalog.pg_class c2 ON c2.oid = i.indexrelid JOIN pg_catalog.pg_class class ON c.oid = class.oid JOIN pg_catalog.pg_namespace n ON n.oid = class.relnamespace LEFT JOIN pg_catalog.pg_constraint con ON (conrelid = i.indrelid AND conindid = i.indexrelid AND contype IN ('p')) LEFT JOIN pg_catalog.pg_indexes pi ON pi.schemaname = n.nspname AND pi.tablename = class.relname AND pi.indexname = c2.relname WHERE n.nspname || '.' || class.relname = '$YB_TABLE_NAME' AND (SUBSTR(pg_catalog.pg_get_indexdef(i.indexrelid, 0, true), POSITION('lsm' IN pg_catalog.pg_get_indexdef(i.indexrelid, 0, true))+4) ILIKE '%HASH,%' OR SUBSTR(pg_catalog.pg_get_indexdef(i.indexrelid, 0, true), POSITION('lsm' IN pg_catalog.pg_get_indexdef(i.indexrelid, 0, true))+4) ILIKE '%HASH\)%') ORDER BY i.indisprimary DESC, i.indisunique DESC, c2.relname) SELECT REPLACE(REPLACE(x_1, '(', ''), ')', '') FROM (SELECT SUBSTR(x, 1, CASE WHEN POSITION('HASH,' IN x)-1 <= 1 THEN POSITION('HASH)' IN x)-1 ELSE POSITION('HASH,' IN x)-1 END) || ')' x_1 FROM q) foo ORDER BY LENGTH(x_1) DESC LIMIT 1;"`
# If there are no HASH sharded columns, do not attempt to compute row count
if [ -z "$HPC" ]
then
echo "No HASH sharded columns detected."
exit 1
fi
fi
# Get the list of T-Servers if UYS = 1
if [[ "$UYS" == 1 ]]; then
HOSTS=`y -Atc "SELECT string_agg(host, ',') host FROM yb_servers();"`
IFS="," read -a HOSTS_A <<< $HOSTS
else
HOSTS=$2
IFS="," read -a HOSTS_A <<< $HOSTS
fi
# Remove temp file
rm -fr $TMP_OUT_FILE
START=0
INC=$((65536/$RCS))
END=$((65536-$INC))
for COUNTER in $(eval echo "{$START..$END..$INC}")
do
RAND=$[$RANDOM % ${#HOSTS_A[@]}]
y1 -h ${HOSTS_A[$RAND]} -Atc "SELECT COUNT(1) FROM $YB_TABLE_NAME WHERE yb_hash_code($HPC) BETWEEN $COUNTER AND $(($COUNTER+$INC-1));" >> $TMP_OUT_FILE &
#echo "SELECT COUNT(1) FROM $YB_TABLE_NAME WHERE yb_hash_code($HPC) BETWEEN $COUNTER AND $(($COUNTER+$INC-1));"
done
wait
# Display total row count as sum of row count subsets
awk '{ sum += $1 } END { print sum }' $TMP_OUT_FILE
# Remove temp file
# rm -fr $TMP_OUT_FILE
exit 0
Example:
I have a three node cross region YugabytedDB database:
[yugabyte@ip-10-36-1-66 ~]$ ysqlsh -h 10.36.1.66 -c "SELECT host, cloud, region, zone FROM yb_servers() ORDER BY region;"
host | cloud | region | zone
-------------+-------+-----------+------------
10.36.1.66 | aws | us-east-1 | us-east-1a
10.38.1.218 | aws | us-east-2 | us-east-2a
10.42.1.210 | aws | us-west-2 | us-west-2a
(3 rows)
I’ll be running my script from the us-east-1 region, so I want to avoid connecting to the node in us-west-2. In a single-region database, it wouldn’t be an issue to connect to all three nodes since the latency between availability zones is minimal.
First, let’s see how long it takes to get a row count using the traditional method.
[yugabyte@ip-10-36-1-66 ~]$ ysqlsh -h 10.36.1.66 -c "\timing" -c "SELECT COUNT(*) FROM test.t1;"
Timing is on.
count
-----------
200000000
(1 row)
Time: 31450.210 ms (00:31.450)
Now let’s give the Bash script a go…
[yugabyte@ip-10-36-1-66 ~]$ time ./quick_row_count.sh test.t1 10.36.1.66,10.38.1.218 yugabyte yugabyte c1
200000000
real 0m11.426s
user 0m0.275s
sys 0m0.540s
The time required decreased from approximately 31.5 seconds to 11.4 seconds.
[yugabyte@ip-10-36-1-66 ~]$ ysqlsh -h 10.36.1.66 -c "SELECT (((31.5-11.4) / 31.5) * 100)::NUMERIC(5, 2) AS \"% Increase in Perf\";"
% Increase in Perf
--------------------
63.81
(1 row)
Have Fun!
