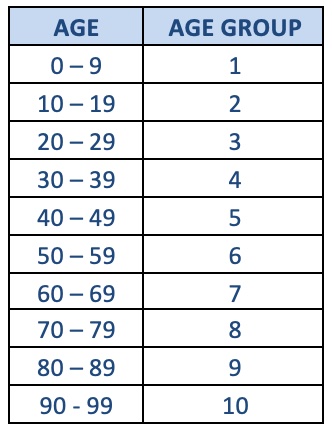
yugabyte=# SELECT name,
age_avg,
width_bucket(age_grp, 0, 99, 10) agr_grp
FROM tv_show
ORDER BY width_bucket;
name | age_avg | age_grp
-----------------------+---------+---------
Wiggles | 7 | 1
SpongeBob SquarePants | 11 | 2
Family Guy | 18 | 2
American Idol | 25 | 3
Dallas | 33 | 4
Arrested Development | 32 | 4
Modern Family | 32 | 4
Wheel of Fortune | 42 | 5
Dancing with DBAs | 42 | 5
Murder She Wrote | 53 | 6
CSI: NY | 58 | 6
Magnum P.I. | 60 | 7
Blue Bloods | 63 | 7
Golden Girls | 63 | 7
Andy Griffith Show | 91 | 10
60 Minutes | 100 | 11
(16 rows)